ʹ���������ʽ������Ͳ���.
�������ʽ��һ�����ַ������ҵ���ȷ�����ַ����ļ���.�������ʽ�Ǿ������⺬����ַ�����ͨ�ַ�����ϵ��ַ���,��ʾĿ���ַ����п��ܸ��ĵ�����.AutoIt�е��������ʽĬ������²����ִ�Сд.
�������ʽ��һ���������������.������Ų����±���,��ô��ֻ��Ӧ������.
�ظ�����(*,+,?,{...})����Ӧ������ַ���(̰��ƥ��),�������������֮�����ʺ�'?',ģ���һ���ֽ���Ӧ����С���ȵ��ַ���(����ƥ��).
ע��:����ȷ���������ʽ���ܵ���ѭ��,��������"TCIMG"����.
���������Ԫ�ַ�
() |
���ַ�����Ϊ�������,����(text).����ƥ������ַ�����ֹ����,�Լ���һ��ʹ�ø�����. |
[] |
������Ϊһϵ���ַ���һ���ַ���Χ����,����[a-z].ƥ����ʾ��Χ�ڵ�һ���ַ�,�б��ͷ�Χ���������һ��,����[a-zA-Z];��ʹ���ظ���������. |
{min,max} |
ƥ��ǰһ���ַ��ظ�min��max��,����{3,8},����,{3}��ʾ��ȷƥ��3��,��{3,}���ʾƥ��3�λ����. |
ת���ַ�,ת��Ԫ�ַ���Ϊ�����ַ�(\\��ʾ\,\.��ʾ.,\[��ʾ[,\]��ʾ],\{��ʾ{,\}��ʾ},\*��ʾ*). |
|
^ |
ê���п�ʼ(������ı��е���ͷ),����^text text$,��ռ�ַ�λ |
$ |
ê���н���(������ı��е���β),����^text text$,��ռ�ַ�λ |
. |
���˻���֮��������ַ���Ĭ��.����(?s)�C��ƥ�������ַ� |
| |
��(or).����ƥ��|ǰ���ַ�Ҳ����ƥ��|֮����ַ�.ͨ����һ������,����(10|20) |
? |
����ƥ��,ǰ�ַ��Ƿ����,ƥ�������������ַ�,�ɶ�̰��ƥ��������,��-(.*?) |
* |
̰��ƥ��,�ظ�ǰһ�ַ�����0����,ƥ�������ܶ����ַ� |
+ |
̰��ƥ��,�ظ�ǰһ�ַ�����1����,ƥ�������ܶ����ַ� |
�������ڵ�Ԫ�ַ�
�������а�����ģ���һ���ֳ�Ϊ�ַ���.��������,Ԫ�ַ�ʧȥ�����⺬��,�����ڴ����Ԫ�ַ�����.ֻ��4���ַ���Ҫת��\-][.
���" - "�ַ���ö�ٽ���ʱ,����Ҫת��.������ģ����ʹ��ͨ���Ԫ�ַ�,����ʹ�ñ߿�Ԫ�ַ�,����\A,\B,\Z,\z,
\b�ַ���ʾ�˸��ַ�.��ע�ⷶΧ,����[��-��]ʹ��UTF-8����,������ASCII.
ת���ַ� |
|
^ |
���ִ���λʱƥ���������е�����һ���ַ�.����[^3]��3��������1���ַ� |
- |
������,����[a-z],����a��z��������� |
[] |
�ַ��������Ŀ�ʼ�ͽ���,����[a-z] |
ͨ���Ԫ�ַ�
\1-\9 |
��������,����ģ�屾�����滻ģʽ�в�����������,\1��������1ƥ����ı� |
$1-$9 |
ָ���滻ģ�����ҵ����飨9�������ƣ� |
$0��\0 |
������ȫ��ģ��ջ |
\a |
Chr(7)-�����ַ�(Ч���ǵ�����һ��)ASCII-ʮ����7.BEL(hex 07) |
\cn |
����Ctrl+n��ϼ�ʱ�����Ŀ����ַ�,����nΪ�ַ�,����\cD��Ӧ��Ctrl+D.\cA=\001,\cZ=\032,\cM=\r=\015 |
\e |
Chr(27)�Cƥ��escape(hex 1B) |
\f |
Chr(12)�Cƥ���ҳ��(hex 0C) |
\h |
[\t]�������ո�,�Ʊ���-Chr(9),Chr(32),Chr(160) |
\H |
[^\h]�C�ǿո���Ʊ����ַ� |
\K |
����ƥ�俪ʼ. |
\n |
@LF,Chr(10)-���з�(hex 0A) |
\N |
[^\n]����ǻ��з�(��@LF).3.3.6.1�汾����Ч |
\Q...\E |
\Q��\E֮�������Ԫ���ű���Ϊ�ı�.���ų�����\QD:\Edit\1.txt\E |
\r |
@CR,Chr(13)-�س�����(hex 0D) |
\R |
[\n\f\r\v]Chr(10),Chr(11),Chr(12),Chr(13)����з� |
\t |
@TAB,Chr(9)�Ʊ���-tab(hex 09) |
\v |
[\r\n\f]Chr(10),Chr(11),Chr(12),Chr(13)��ֱ�Ʊ�(@CR��@LF�ͷ�ҳ��) |
\V |
[^\v]�C����Ǵ�ֱ�Ʊ��ͷ�ҳ��Chr(10),Chr(11),Chr(12),Chr(13)(����) |
\x** |
����*-����ʮ�����������ַ�,����\x41��Ӧ��������ĸ'A',\x50\x65\x72\x6C�C��ʾPerl |
\x{**..} |
����*-����ʮ����������,����\x{50}\x{65}\x{72}\x{6C}-��ʾPerl.\x{01}��\x{7F},ʮ����ϵͳ�б�ʾ��1��127����.����\x{044F}��UTF�����е��ڷ���"���" |
\*** |
����*-����λ�˽�����(ǰ��0)\120\145\162\154Perl(\120-�˽��ƴ�����ĸP,\145-��ĸe,\162-��ĸr,\154�C��ĸl).�ո�-\040.ȡֵ\001��\177,��Ӧ����ʮ���Ʒ���1��127 |
\G |
��ǰ���������ĵ�(�����еĵ�һ��ƥ��λ��) |
Ԫ�ַ��Cָ���ַ���Χ
\d |
[0-9]-����ʮ�������ֵ��ַ� |
\D |
[^0-9]���ⲻ��ʮ�������ֵ��ַ� |
\s |
[\f\n\r\t\v]�C����հ��ַ�:Chr(9),Chr(10),Chr(12),Chr(13),Chr(32)(ҳ�滻��,�Ʊ���,�س�,���кͿո�). |
\S |
[^\f\n\r\t\v]-����ǿո��ַ� |
\w |
[0-9a-zA-Z_]-������ĸ,�����ַ����»���(��������ĸ�ķ���) |
\W |
[^0-9a-zA-Z_]-����ǵ����ַ� |
�ַ��߽�
\A |
�ı��Ŀ�ʼ,�������ڱ�־"(?m)",ֻ����һ�� |
\z |
�ı��Ľ�β,�������ڱ�־"(?m)",ֻ����һ�� |
\Z |
�ı��Ľ�β,��������ź��ı���β,��ֱ���ַ�\n,��������ڱ���ʽĩβ,�������ڱ�־"(?m)",ֻ����һ��. |
\b |
ƥ�䵥�����ǵ����ַ�֮��ı߽�,һ��ƥ��\W,һ��ƥ��\w(������������ĸ���ʵı߽�) |
\B |
�����������ǵ����ַ�֮��߽�,������ͬʱ����\W��\w |
��־���η�
�����������ʽ����Ŀ�ͷ,���������ʽ����������
���η���״̬Ĭ���ǽ��õ�,���Ա������ú����ʹ��.
ʹ��ʾ��:(?i)(Text)��((?-i)Text)
�����ϲ�:(?is)(Text)��((?imsx)Text)
(?i) |
�����ִ�Сд,��ֻ�����������ַ�. |
(?-i) |
ȡ��(?i)����,(?-x)��ʾȡ���˱�־ǰ(?x)������,��ͬ |
(?m) |
�ڶ����ı��з���^��$�ֱ��ʾ�еĿ�ʼ�ͽ���,�����ʾ���ı��Ŀ�ʼ�ͽ��� |
(?-m) |
ȡ��(?m)���� |
(?s) |
��ѡ����þ��(.)ƥ��������з�@LF���ڵ������ַ�(һ�������,������ƥ�����з�).("һ���ַ���"ģʽ) |
(?-s) |
ȡ��(?s)���� |
(?x) |
ע��ģʽ,�������������ʽ������֮��Ŀո�����ʹ��#��Ϊע��.ʹ��������.ʾ��ע��-(?#Text).���������ԣ����ź����������ǰ����ı�,������ֱ�����������ʽ����ע��. |
(?-x) |
ȡ��(?x)���� |
(?J) |
�����ظ������ƣ������ظ�/˫������.�� |
(?U) |
����̰��ģʽ���� |
(?-U) |
ȡ��(?U)���� |
���־
��־�������,����(?im-sx:Text),����im,�ر�sx.
(?i:...) |
������ʹ����־���η�.(?i:Text) |
(?-i:...) |
������ȡ��ʹ����־���η�.(?-i:Text) |
(?:...) |
ƥ��Text,��������ƥ����ı�,Ҳ�����˷���������(?:Text) |
(?>...) |
����������������,���߱�̰������(?>Text)(Text) |
(?=...) |
�������Ԥ�����ж���,����Text���ֵ�λ�õ�����ƥ�����ʽ(Text)(?=Text) |
(?!...) |
����ȸ�Ԥ�����ж���,����Text����������ƥ������ʽ.(Text)(?!Text) |
(?<=...) |
��������ع˺���,ƥ��Text�����λ��(?<=Text)(Text) |
(?<!...) |
����ȸ��ع˺���,ƥ��ǰ�治ƥ��Text��λ��,����:(?<!Text)(Text) |
(?<name>...) |
ƥ���ı�,�������ı�������Ϊname������,��Ϊ�����ο�.����һ��ָ��������,ʹ��\k<name>.Ҳʹ��\1��$1 |
(?#...) |
�������͵ķ��鲻���������ʽ�Ĵ�����������Ӱ��,�����ṩע�������Ķ�,����:(?#����һ��ע��). |
�ظ��ַ��CӦ�����ַ�����(����)
{n} |
��ȷƥ��ǰһ���ַ��ظ�n�� |
{n,} |
ƥ��ǰһ���ַ��ظ�n������,�����������ظ�{n,}? |
{n,m} |
ƥ��ǰһ���ַ��ظ�n��m��(��){n,m}? |
* |
ƥ��ǰһ���ַ��ظ�0������.��{0,}ͬ��.̰��ƥ��,��ƥ�������ܶ����ַ�. |
+ |
ƥ��ǰһ���ַ��ظ�1������.��{1,}ͬ��.̰��ƥ��,��ƥ�������ܶ����ַ�. |
? |
ƥ��ǰһ���ַ�����1�λ���.��{0,1}ͬ��.�����ظ��ַ����?��:.*?�C����ƥ��,������ |
*? |
ƥ��ǰһ���ַ��ظ�0������,������ģ�����ಿ��ƥ�����С����(����ƥ��) |
+? |
ƥ��ǰһ���ַ��ظ�1������,������ģ�����ಿ��ƥ�����С����(����ƥ��) |
?? |
ƥ��ǰһ���ַ��ظ�0��1��,����[a-z]??'gg'����2������ |
����̰��ƥ��
��������ع���ǰ����.����ƥ��ǰһ�ַ���һ����ʽ.����ƥ��ģ������ಿ��.����ʽ��Χ����ַ���Ӧ������̰����ƥ��,����ģ�彫������ȷ����,������������ij���̰��ƥ��ΨһĿ�ľ��Ǽ�����������.
*+ |
ƥ��ǰһ���ַ��ظ�0������. |
++ |
ƥ��ǰһ���ַ��ظ�1������. |
{n,}+ |
ƥ��ǰһ���ַ��ظ�n������. |
POSIX���ַ���
��[[:upper:]]{2}-�����ظ��Ĵ�д��ĸ.
��ת��Χ:[[:^digit:]]
[:alnum:] |
��ĸ������[0-9A-Za-z](��\w,����"_") |
[:alpha:] |
��ĸ[A-Za-z](����"_") |
[:ascii:] |
����,��Chr(0)��Chr(127) |
[:blank:] |
�ո���Ʊ����ַ�Chr(9)��Chr(32),��[\t]ͬ�� |
[:cntrl:] |
�����ַ�Chr(0)Chr(31)��Chr(127) |
[:digit:] |
ʮ��������,��\dͬ��,[0-9] |
[:graph:] |
�ɴ�ӡ�ַ�,���ʱ��[:print:]ͬ��,�ո����(��Chr(33)��Chr(126)) |
[:lower:] |
Сд��ĸ,��[a-z]ͬ��. |
[:print:] |
��ӡʱ��ʾ�ķ���,�����ո�(��Chr(32)��Chr(126)) |
[:punct:] |
�ɴ�ӡ�ַ�,�ų����ֺ�����Chr=(33-47,58-64,91-96,123-126),������[:alnum:],��[:cntrl:] |
[:space:] |
�հռ�(����ȫ��\s��ͬ,������VT:Chr(11))Chr(9)Chr(13)��Chr(32).����[\f\n\r\t\v] |
[:upper:] |
��д��ĸ,��[A-Z]ͬ��. |
[:word:] |
���ַ���\w |
[:xdigit:] |
ʮ��������[0-9A-Fa-f] |
������ģʽ
(?(exp)yes) |
��(?(?=[a-z])\d),��exp��������������ж���,��������λ����ƥ��,ʹ��yes��Ϊ����ı���ʽ |
(?(exp)yes|no) |
��(?(?<=\d)a|b)��(?:(?>(?=[^a-z]*[a-z])())?(?:(?=\1)aa|(?!\1)1)),��exp��������������ж���,��������λ����ƥ��,ʹ��yes��Ϊ����ı���ʽ,����ʹ��no |
(?=[\w]+)|(?R) |
�ݹ���� |
AutoIt3����Щ��־��������
\p |
��������� |
\l |
�������ʽ����һ���ַ���ת��ΪСд. |
\u |
�������ʽ����һ���ַ���ת��Ϊ��д. |
\L...\E |
\L��\E֮����������ʽ�е����з��Ŷ���ת��ΪСд. |
\U...\E |
\U��\E֮����������ʽ�е����з��Ŷ���ת��Ϊ��д. |
\x |
����ʮ�������ַ� |
\< |
һ�����ʵĿ�ʼ,\W���ź�\w����֮��ı߽� |
\> |
һ�����ʵĽ�β,\w���ź�\W����֮��ı߽� |
{,n} |
ƥ��ǰһ���ַ��ظ�0��n��. |
ʵ��
.* |
�ظ������ַ�,�⼴�����ı� |
[...] |
�����ַ��ļ���,����[aeiou]-����Сд��Ԫ�� |
[^...] |
û�м��ϵ���һ����,����[^aeiou]-ûһ��Сд��Ԫ�� |
[0-9A-Fa-f]{6} |
ʮ����������,ƥ��FF0000. |
[��-��] |
������ĸ�ķ�Χ[��-����-��] |
���� |
����(\r\n|\r|\n){2,}��\1�滻 -ɾ������ |
����(?<![^\s\A])([��-��]+)[\h]+\1��\1�滻 -ɾ�������ظ� |
����[A-Z��-����]{2,}?[a-z��-���]+ -��ʶ�����д���Ķ��俪ʼ�C����д��ĸ |
����(.{35,}?)\h�滻Ϊ$1��@CRLF -��35���ַ����һ��������Ŀո�ı߽�ִ�л���. |
���� (?si)(?:.*?)?(https?://[\w.:]+/?(?:[\w/?&=.~;\-+!*_#%])*) -�������� |
����[A-Za-z0-9._-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}) �C�������� |
Ϊ��ѧϰ��ϰ�������ʽ�����Ƽ�ʹ��regex����(����ע�������汾Ϊ RegExp 2.8)

1.�鿴Library_Example���е�����ʾ��,��Ȼ��������ʾ��

2.ע��"�滻"������,��ijЩ�����,��ֻ��Ҫ�ҵ�����.
����Ҫ����������.
���������ʽ��ѧϰ�����⣬������ʡ�Զ���������ʱ��.
���������ڣ�ֻ����һ�£����������滻���Ϳ��Խ�����⡣
��������������У������������������Ҫ�ģ�������Ҫ�ģ�
��Total Commander�� - �����������У��������Ի�����...
���ı��༭��AkelPad��...
���Ӳ��Ҳ�ѧϰ�������ʽ���㽫�ᱻ������
������һЩ����:
1.��Ҫһ���ӳ���ѧϰһ��.������Ҫ֪���������ʽ�����й���.
2.ʹ���������ʽ�������ʱ:
a)�Լ�����
b)������ɹ����Ķ��������
c)�����
(ѧϰ˳�����Ҫ)
3.��ʵ���о�.�ڻ�������,������ҵ��㹻������.
4.��¼����,�����ȥ�ɹ�������.
��������һ��������(��ʹû���������ʽҲ����ִ������).
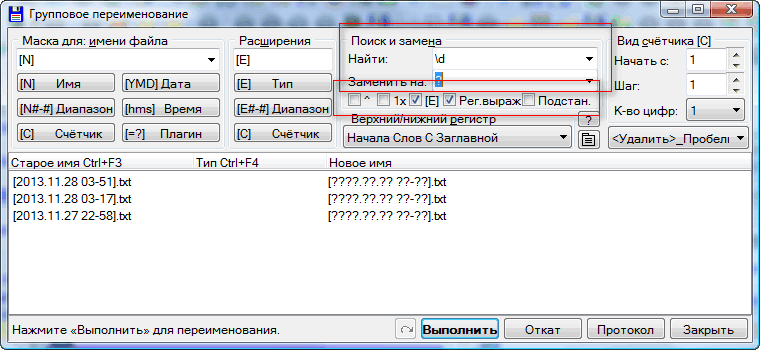
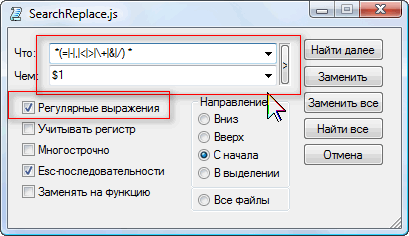
��һ���ַ��� coverAbout
����ֻ��Ҫ���� About
������Ӧ��ͼƬ�е�����.
1.��ѡ��ť����Ϊ"�滻"
2.���ı�����,�����ַ��� coverAbout
3.��ģ���ֶ��д����������� cover(About)
4.�����滻���� $1
5.���"����"
6.�������һ����ȷ,��ô"�������"��������ȷ�Ľ��
----
7.�й�������Ϣ
8.�����Ա���ģ��

![]() © ���ӧ֧�ڧ� ���ߧէ�֧� �էݧ� Total Commander Image Averin-And@yandex.ru
© ���ӧ֧�ڧ� ���ߧէ�֧� �էݧ� Total Commander Image Averin-And@yandex.ru